![[SJF Logo]](../../images/sjflogo.gif)
Kasia is not the only one with a gripe about stupid banks.
Credit card fraud is a huge problem, and the card issues are getting pretty aggressive about calling consumers to verify purchases that might be "suspicious", but I am astonished how dumb their systems are for this. I suppose there are people who use their credit cards once a year for some special purpose, but I am not one of them. I use my cards all the time, and it's hard for me to keep track of all the dollar amounts in my head.
So, when I got the call tonight for a purchase of $1016.73 for "Business Services", I wasn't sure what it was. Who was the merchant? "We don't know". OK, then were was the charge from (I had just made a purchase about that size from France). "We don't know: just 'business services'".
This is so dumb I can hardly see straight: these people have invested a fortune in computerized electronic transaction systems (and I have written a lot of software to talk to them), but they don't know who they're sending my money to? All I can do is shrug and say "Well, that sounds about right" and move on. This doesn't provide very much fraud protection at all.
And it's not that I am unanxious to help: I've had two of my cards used fraudulently in the last six months, and since both (relatively small) transactions were out of the country, I had to close the accounts and reopen them. It's a huge pain, and I'm happy to help keep my costs down by busting fraud.
But this is just dumb.
I just installed Adobe FrameMaker 7.0, which is high-end document managment software: software like Microsoft Word is just not suitable for large complex documents such as "books" and the like. The CD it came on had around 500 megabytes of data, which is about what one would expect: installers, the program, help files, samples, templates, and the like.
This was an upgrade from a previous version (which the installer had to find before it would continue), so I dug in my software closet for my old product box. I had been using version 3 from 1992, and the entire product was delivered on four floppies (and if you don't install the templates and examples, it only uses the first two). The current FrameMaker 7.0 binary - just FRAMEMAKER.EXE - is 4.5 megabytes.
I don't actually bemoan this, really: this software is so much more capable than the previous versions, and I like having all the examples and auxilliary data provided. Hard disk space and RAM are more or less free these days, and I'm not so sure that time spent on "footprint reduction" is really any better spent than on "quality control" or "adding useful features".
But it does make me feel like a dinosaur for my own concern with minimizing the size of my own software. I remember when adding a feature to my nbtscan tool caused the size to go up: NBTSCAN.EXE is now 36,864 bytes.
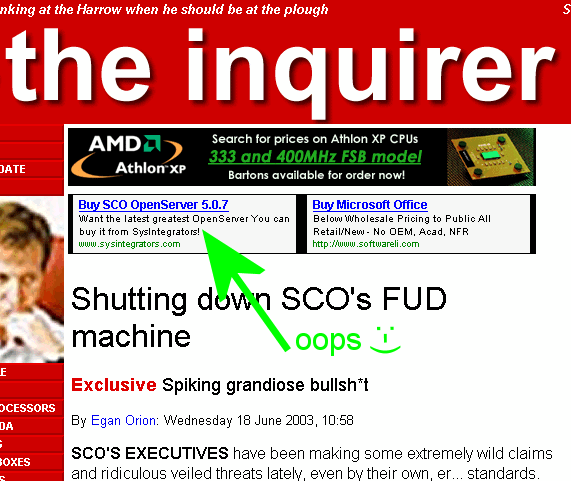 I've been following the whole SCO mess with much more of an open mind than most in the open source community: I do have respect for intellectual property, and I am more aware of the history of UNIX than most of those who weren't even born when I started using it (January 1981). I have been clear in my own mind to separate "SCO is going about this badly" from whether they might have a valid claim or not.
I've been following the whole SCO mess with much more of an open mind than most in the open source community: I do have respect for intellectual property, and I am more aware of the history of UNIX than most of those who weren't even born when I started using it (January 1981). I have been clear in my own mind to separate "SCO is going about this badly" from whether they might have a valid claim or not.
I'm tending to think more and more that they do not, mainly because they won't reveal any of their evidence. They claim it's because they don't want people to rip out the offending code before it gets to trial, but I think this shows a misunderstanding of "internet memory" - you can't make anything go away on the internet even if you try (and the Scientologists have surely tried).
At any rate, The Inquirer ran an interesting piece (amusing screenshot above) on an approach to actually compare various pieces of source code to look for borrowings by taking fingerprints of both trees. Each source file would be broken up into five-line chunks, and an MD5 checksum of each chunk taken and published, and it would allow distribution of the checksums without revealing the source code.
The approach proposed in the article was simpleminded - but a great start - and there is a much better approach. Former Yahoo! Chief Scientist Udi Manber (now at Amazon.com) came up with an algorithm for finding similarities in files, and it's based on a more advanced fingerprinting technique.
This paper, Method for Identifying Versioned and Plagiarised Documents by Hoad and Zobel (RMIT, Australia), which references Udi's algorithm, describes an approach which appears to be a good candidate. In particular, it should be much better than simpleminded MD5 checksums of five-line chunks that can be fooled by changing even a single character in that chunk.
The algorithm is more than "are they the same?", but it can detect co-derivatives, such as two files that came from a single source, and by producing a large file of these fingerprints for the System V source code, one could cross-compare it with the Linux source.
Interestingly, the algorithm allows one-to-many comparisons, so you'd not have to know that file1.c in the Linux source base implemented the same functionality as file2.c in System V - it will find all the likely matches in a huge n-by-n matrix.
As an aside, I met Dr. Manber when I visited Yahoo!, and it was clear why people like him are "Chief Scientist" types and I will never be. When this man walks down the hall, algorithms fall out of his pocket: some of them are just stunning. I'm great at implementing algorithms, but thinking them up is not my strong point. *sniff*
And he's a really nice guy too. Yahoo!'s loss is Amazon's gain, that's for sure.
How many times have you written a shell script that needed to add (say) three days to the current date? This kind of thing came up for me all the time, and it's much harder than it looks (leap years, variable days in a month, etc.). In the late eighties I wrote a yacc-based tool that did most kinds of reasonable math with dates, and it was meant to be used from a shell script:
Today I finally bundled it all up, got it working correctly with flex (the lexer) and bison (the GNU parser), and wrote a web page for it. Distributed in source form.$ datemath today + 5 06/23/2003 $ datemath 12/25/2003 - today 188 $ datemath today + 5 weeks 07/25/2003
 In the local supermarket card-club, a recent receipt showed that I could get $10 off a bottle of wine on my next visit, and reading the fine print it shows that this coupon is not good for alcohol. Easy to be generous when you never have to give it up, I suppose.
In the local supermarket card-club, a recent receipt showed that I could get $10 off a bottle of wine on my next visit, and reading the fine print it shows that this coupon is not good for alcohol. Easy to be generous when you never have to give it up, I suppose.
Recently for a customer project, I had a need to add items to the right-click menu for items (had a file-type-specific action we needed to perform), and it was clear I was not going to figure this out on my own. So trusty Google brought me to jfitz technologies, which is a dandy site for Windows (and other things) resources.
The Customizing Right-Click Menu Options in Windows tip was exactly what I needed, and it was very well written with plenty of screen shots. It confirmed that I'd never have figured it out on my own. This is not the only "Free Advice" of his I've used.
Thumbs up to John Fitzgibbon for a great resource.
I've long had a practice of always building internet-facing software from source obtained directly from project mirrors, though I have been surprised how few of my friends -- including the very skilled ones -- follow this same practice. But putting aside the "rpm/apt-get/up2date/emerge" versus "source" religious debate for now, I decided to codify my build-from-source practices in a Tech Tip.
Some time ago I started parking all of my "configure" options in a front-end script that is actually used to build the software, and it's been a huge win. This goes beyond simply making notes: the build options are now part of source code, and I've been completely delighted with it. I hope that others who build from source find it as useful as I have.
Unixwiz.net Tech Tip: Good practices for building packages from source
LINDON, Utah, June 13, 2003 -- The SCO® Group (SCO)(Nasdaq: SCOX), the owner of the UNIX operating system, announced today that it was filng suit against The SCO® Group (Nasdaq: SCOX) for illegal inclusions of SCO UNIX intellectual property in SCO Linux.
"SCO is taking this important step because there are intellectual property issues with Linux," said Chris Sontag, senior vice president and general manager of SCOsource. "When SCO's own UNIX software code is being illegally copied into SCO Linux by our own employees, we believe we have an obligation to put a stop to this. We felt that using the legal system as a first step would be more productive than simply talking to the other department about it quietly. We're trying to make a point here".
It also indicated that it may pursue legal action against the customers of the SCO Group who continue to use SCO Linux in the light of this action, and has begun the process of serving itself with a subpoena duces tecum for a full and complete customer list. "We have a right to know where our intellectual property is being used", said Sontag.
When asked to respond to the lawsuit, a spokesman for the SCO Group had no comment.
---
for the humor-impaired: this is a joke. SCO has been suing everybody over this lately
I created some software that decodes obscured AOL IM passwords stored in the registry, and it's intended for use by people doing penetration testing and security analysis. It's not meant as a hacker tool, and it's not packaged in a way that can be used easily without some level of skill. I have an explicit disclaimer that I don't provide tech support for this unless it's clearly of the level of debugging the code. In particular, I don't help recover passwords.
But then I recieved this email some time ago:
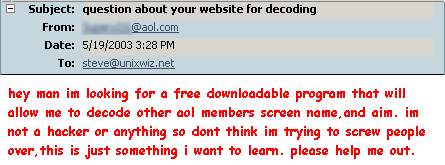
Oh, in that case: no problem. As long as you're not a hacker or trying to screw anybody over, I'm more than happy to help.
![]() Previously I wrote about my irritation with the "No dashes or spaces" restriction on credit card fields on web forms, and just this morning ran into two more sites that did this. Enough: how hard could this be?
Previously I wrote about my irritation with the "No dashes or spaces" restriction on credit card fields on web forms, and just this morning ran into two more sites that did this. Enough: how hard could this be?
"No Dashes Or Spaces" Hall Of Shame