![[SJF Logo]](../images/sjflogo.gif)
We were recently retained by a customer to extract data from an application running Sybase Adaptive Server Anywhere 6 on Windows NT, and this details the steps taken to get the data out in a reasonable time and in a way that the customer could reproduce without our help. The target audience here is the consultant generally skilled in databases and problem solving but doesn't know Sybase all that well. We were in this very same boat until just before this project.
We expect that the approaches taken could apply to other Sybase releases and perhaps to other databases in general.
Quick links:
The prospective customer installed a modem on the NT 4.0 Server and enabled pcAnywhere dialin access: we were able to dial in for a couple of hours each evening during the window between end-of-business and when the backup kicked in. This system had no internet access of any kind.
Nobody involved knew anything about the Sybase specifics, including any of the database passwords involved. This was apparently a turnkey application, and we presume that the competitive vendor would not likely be forthcoming with this information. The circumstances were also such that we didn't care to press the prospective customer too much, so we were largely on our own.
By way of conversation, "GoodApp" is our customer's application, and "SadApp" is the competitive one run by the prospective customer.
Sybase documentation for the release we used can be found at http://sybooks.sybase.com/awg0603e.html.
Information about achieving sa access in other versions of Sybase can be found on this web server here.
One important note: Microsoft SQL Server is based on Sybase, and though they have diverged as the products each took on their own lives, there is much that is in common between the two. We were fortunate to leverage our MS-SQL experience when solving this Sybase problem.
Our primary vehicle for working with the database was DBISQL.EXE, an interactive SQL interface. This Windows GUI had sub-windows for commands, data, and error output, and it was sufficient to do everything we needed.
When launching DBISQL, you'll be asked for connection information via this dialog box:
You'll be given three ways to connect: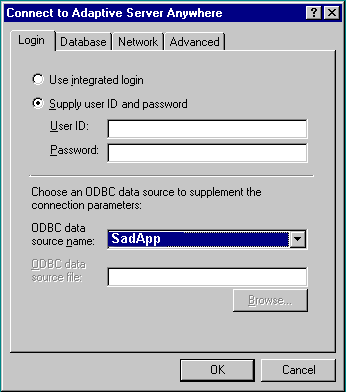
Once attached to the database - by whatever method - you can then issue the usual SQL queries that one does when digging around. These are a few of the tidbits we found most helpful. Note that this is not a reference work, and we skip over many details that can be gleaned from the documentation. We just wish to give a starting point.
"Integrated"
- In this mode, your NT credentials are presented to Sybase and they are associated with an underlying database user. This must be set up in advance, and many systems associate the NT administrator with the Sybase administrator. This is worth trying first if you are in the system as admin, though in our case SadApp wasn't configured to use this at all. We believe we could have enabled it, but this was a production system and we were very nervous about touching active database parameters.
- Here you present a database username and password, and these have nothing to do with any NT users. We'll see these users listed later on, but for the time being we didn't have any access this way.
- Many applications use an ODBC driver between them and the database, and it's managed via the Windows Control Panel "ODBC" applet. It turns out that SadApp used this interface, and by looking into the registry, we were able to learn the parameters used to connect with the database.
The registry key HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI\ contains sub-keys for each configured data source, and in our case it was obvious which one was used by SadApp. Under that key were UID and PWD values that contained the user name and password, respectively. We'll refer to SadUser as our DB username.
Strictly speaking we didn't need this information - DBISQL was more than happy to use the ODBC connection - but if this approach yields a dba password it means you'll have full run of the database.
- This stored procedure produces a list of all tables in the system in a relatively readable format, and it's really just a convenient front end to a SELECT on SYSTABLE. Each table in Sybase has a name and a creator, and these two together form the full name of the table: if user steve and user jeff create a table named "customer" in the same database, steve.customer is a distinct table from jeff.customer.
- Given a table name and creator (but not in the usual creator-dot-tabname format!), this produces a tabular listing of the columns in that table along with type and size information.
- This produces a tabular list of all database users, and it may give some clues where to look in the system for getting higher access than is available now. In many cases, the actual users of SadApp don't really know what "kind" of user name they use to get into the system: NT user name? Database user name? Application user name? By getting this list we were able to see what to look for.
- The ># notation routes the output of command into the given output file, and we observe that it works with regular SQL commands or stored procedures. The filename should not be in quotes, and even on Windows platforms, UNIX-style forward slashes seem to work just fine. If >># is used, the output is appended to the file.
We'll note, however, that the output generated to the file does not look the same as that appearing in the "Data" window in DBISQL. The output file gets more of an "unload" format that is hard to read but probably easier to parse. It's not clear if it's possible to get "readable" output redirected to a file.
- As with >#, this reroutes output to the given file, but also includes the error messages and statistics. If >>& is used, the output is appended to the file.
- This command-line utility is used to perform database unloads, but we were never able to get past what we think were permissions issues. Normally, the -c parameter is used to specify connection information, and in our case it should have been:
C> DBUNLOAD -c "uid=SadUser;pwd=sadpass" ...paramsbut we think that SadUser didn't have enough permission. But it's worth investigating if your situation permits it (especially if the configuration supports integrated security mode).
There were way too many tables (hundreds) to extract by hand, so we instead elected for an automated approach. We used the sp_tables stored procedure to create a text file containing the list of all tables in the system as a base, then used a perl program to create a pair of SQL scripts from that data: The first extracted all table schemas, and the second actually unloaded the data. This approach has proven to be quite promising.
The process started by extracting the full list of tables, and this was done via the DBISQL command:
sp_tables ># C:\UNLOAD\TABLES.TXTWe created the makescripts.p perl program to take this file and create the output scripts, and these scripts can be directly loaded into DBISQL to perform the actual extraction operations. makescripts.p does no database operations of any kind - this is strictly a text-processing application.
We'll study the generated script output first.
sp_columns TABLE1,app ># C:/UNLOAD/schemas/app_TABLE1.sql; sp_columns TABLE2,app ># C:/UNLOAD/schemas/app_TABLE2.sql; sp_columns TABLE3,app ># C:/UNLOAD/schemas/app_TABLE3.sql; ...
The querydata.sql script - also produced by makescripts.p - likewise contains the UNLOAD commands required to extract data from each table to a data file:
Each of these scripts can be loaded directly into DBISQL via File:Open, and once the script appears in the command window, clicking Execute runs the script and routes the output to the destinations found in the scripts. Extracting of the schemas moves very quickly, and of course the data takes a bit longer.UNLOAD TABLE app.TABLE1 TO 'C:/UNLOAD/data/app_TABLE1.txt'; UNLOAD TABLE app.TABLE2 TO 'C:/UNLOAD/data/app_TABLE2.txt'; UNLOAD TABLE app.TABLE3 TO 'C:/UNLOAD/data/app_TABLE3.txt'; ...
We found that db user SadUser did not have permission to select on a few of the tables, and during the process we received a popup dialog box to this effect: clicking "Continue" allowed the process to continue (albeit without those few tables).
makescripts.p [options] --dir=DIR tablefile
| |
Display a brief help listing reminding of all available |
| |
Show a bit more debugging. This shows most of the input parameters, plus each table that we ultimately do not process due to the --skip parameters. |
| |
The generated script files assume DIR is the top level place to store data on the target system, and this need not be the same as the current system so the path is not checked by this program. The generated scripts will save their output to DIR/data/ and DIR/schemas/ subdirectories. Forward slashes for path separation are allowed even on the NT platform. This parameter is required. |
| |
When processing a line of table data, ignore it if any of the
parts matches ITEM on a case-insensitive basis. The parts
considered are
Multiple --skip options can be included to exclude whatever extraneous tables are undesired. |
| tablefile | This required parameter is the name of the file that contains the exported table data from the sp_tables command described earlier. |
For most applications, the command-line parameters will be sufficiently large that they warrant a small RUNSQL.BAT batch file to contain them (these should all be on the same long line):
Then we simply invoke RUN.BAT to perform all our processing, leaving the two output script files in the current directory. These output scripts are then transferred to the target system for processing.perl -w makescripts.p --verbose --dir=C:/UNLOAD --skip=VIEW --skip=SYS --skip=dbo --skip=archive --skip="SYSTEM TABLE" tables.txt
In our sample case, archive was the creator of a set of tables related to the application but didn't appear interesting to us (all its tables were empty).
We have decoded most of the important fields and have written a second perl program that runs through each file and creates a human-readable version of the schema. fixschemas.p is given a list of *.SQL filenames and creates a set of *.SCH output text files.
C> perl -w fixschemas.p schemas\*.sqlThe resulting schema files are suitable for printing or study.
The schema decoding leaves much to be desired, and (in particular) takes no account of indexes, keys, or referential relationships. All of these could conceivably be extracted from the database, but we have not yet found this necessary.
We'll note in particular that we're fuzzy on exactly how the "width" and "precision" fields are decoded, and we very well could be understanding them wrong.
This code is in the public domain.
Navigate: More Tech Tips